The Fun of the Run (and data visualization)
After two failed training attempts through ice and snow in Canada, I ran my first half marathon in May 2019. As it turns out, I have just enough perseverance for a mild, rainy UK winter.
The anonymous medal collecting dust on my shelf didn’t seem like enough to commemorate a goal I’d been running after for so long. So naturally, I created an elaborate data illustration to always remember it by.

With this year’s race pushed and my training off the rails, I thought I’d explain what goes into a data visualization project like this instead. I’m going to take you through the key steps of the data analytics workflow and how I approach my favourite part of the process.

Frame
It might sound obvious but you need to know what you want to find out before you actually dive into the data.
I didn’t have a problem or hypothesis per se, but I wanted to know “What did my training look like?”. This became my guiding light for this project.
Obtain
To work with data, you have to find it or collect it — and it has to be the right data to help you solve the problem.
You may have access to data but that doesn’t mean its enough. Always think of additional information you may need to complete the full picture.
Data I had access to
My training consisted of just running (in retrospect, this is almost definitely not what you should do). So getting a record of my training seemed easy because I tracked it all on Strava.
The downloadable dataset didn’t include all metrics available in the app (i.e. pace or location), so I contacted Strava to get the full set. This didn’t go well.

In the end, I had to manually (and resentfully) fill in the missing variables.
Data I wanted to include
I wanted my visualization to be really personal. So I added in details Strava couldn’t, like my favourite running routes or mid-run coffee breaks.
Explore
Take the time to understand what you’re working with. Always make sure you can correctly interpret and trust the data.
I do a lot of additional research when it comes to compiling datasets, often starting them from scratch. So for me, working with data is an ongoing exploratory process.
Preparation
Data can be given, found, or collected but it’s rarely ready to go as is. A lot of work goes into ensuring that data is in a format that can be easily analyzed. This may include but is not limited to:
- Making sure the data doesn’t contain incorrect or missing values
- Cleaning the data (i.e. “ïüå´ Monday Blues Run” was a activity title and I had to eliminate these unwanted characters).
- Changing the structure (i.e. using Pivot Table to change the shape).
- Making necessary transformations, like calculations and new columns
Transforming the dataset
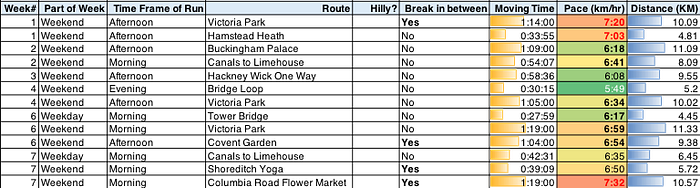
This is an important part so I’ll explain in more detail. I started with the original Strava metrics, which included columns like activity date and time, moving time and distance.
Then I added more detail to the data. For example, Strava gave me the activity date but I created a new column to show the part of week.

To build out my dataset even more, I added personal data points like:
- What route did I take? Was it my favourite route around Shadwell Basin or was I running in Greece on Holiday?
- Did I take a break mid-run?
- Did I remember anything in particular about that run? i.e. an adorable sausage dog in the park.

Analyze
Now that you have collected, cleaned and transformed data, you can finally dig in and answer the questions you want to find out.
While the guiding light for my project was “What did my training look like?” the more detailed questions I was interested in were:
- What did my training look like over time?
- What type of progress did I make and how did it vary by run?
- How was each run unique?
First, I started my analysis in the spreadsheet. I use descriptive statistics like average, min, max, etc. to get a feel for the data and uncover what’s interesting or stands out. These findings lay the groundwork for the visualization concept.
I also see the finished visualization as a means for analysis. I’m a visual thinker (ironically, I’m not a numbers person), and after spending time visualising the data, I can see insights more clearly. So I put my analysis on hold until I finish the next stage of the process.
Present
The last step is about figuring out the best way to share the story you want to tell about the data.
I start this process with the metrics that match the important points from the Analyze step.
- What did my training look like over time?: date, part of day, part of week
- What type of progress did I make and how did it vary?: pace, moving time, distance, route.
- How was each run unique?: route, location, breaks, memories
Then I assign each metric a ‘trait’. A trait simply represents the data differently than the number in the spreadsheet. They are building blocks that fit together to tell the wider story.
Traits can be anything but I wanted to represent how running made me feel. A bright, busy pattern-led design felt like the best way to do that.
Since I wanted to know “What did my training look like over time?” and “How was each run unique?”, I needed to clearly show each run, over the entire period leading up to race day — so that’s where I started.
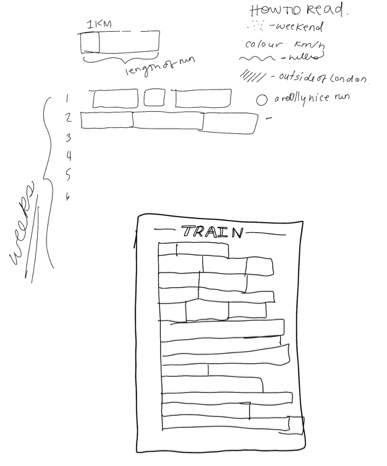
Then I started combining all the different traits to come up with the best design possible. I typically adapt traits as needed to make sure it all fits together nicely. This short clip will give you a sense of the trial and error that goes into starting a visualization.
Once all the traits and overall design is finalized, I created the legend, which is the most important part of for the reader. A legend gives the reader the power to explore the visualization on their own and understand what it means.
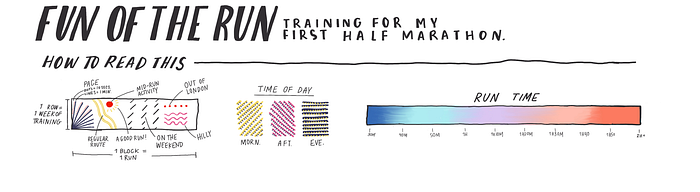
Finally, what sets a skilled data analyst apart from the crowd is the ability to extract insight and advice from the data. Here are my learnings from this project:
- Regular routes are good but if you want to push yourself, switch it up.
- Always pack sneakers while travelling— it’s a memory waiting to be made.
- “Fun Runs” — meeting friends in the middle — are motivating and still contribute to overall progress.
- Mornings are good for regular jaunts and attempts to go a little faster but weekends are the time to go longer.
- Everybody gets to the finish line in a different way. Do what makes you happy — running is personal.
- Mix-up training with some new exercises or your knees will buckle just before you cross the finish line (real talk).
I look forward to my next training season— whenever that may be. Until then, I’ll pass by my Fun of the Run data viz hanging proudly in my flat, perfectly encapsulating my first half marathon experience, while the dusty medal has long since been forgotten.

